这是程序输出的 你好.cpl 的 AST
begin
begin -> stmts
stmts -> import-stmt
import-stmt -> "引入"
import-stmt -> module-list
module-list -> "标准"
module-list -> "."
module-list -> module-list
module-list -> "输入输出"
module-list -> "."
module-list -> "*"
import-stmt -> "\n"
stmts -> decl-stmt
decl-stmt -> "定义"
decl-stmt -> decl-list
decl-list -> "拼接问候语"
decl-list -> "("
decl-list -> argument-list
argument-list -> "姓名"
argument-list -> ","
argument-list -> "性别"
decl-list -> ")"
decl-list -> block-body
block-body -> "{"
block-body -> stmts
stmts -> if-stmt
if-stmt -> "如果"
if-stmt -> "("
if-stmt -> equal-expr
equal-expr -> "性别"
equal-expr -> "=="
equal-expr -> ""男""
if-stmt -> ")"
if-stmt -> block-body
block-body -> "{"
block-body -> return-stmt
return-stmt -> "返回"
return-stmt -> add-expr
add-expr -> ""Hello, Mr. ""
add-expr -> "+"
add-expr -> "姓名"
return-stmt -> "\n"
block-body -> "}"
if-stmt -> "否则"
if-stmt -> if-stmt
if-stmt -> "如果"
if-stmt -> "("
if-stmt -> equal-expr
equal-expr -> "性别"
equal-expr -> "=="
equal-expr -> ""女""
if-stmt -> ")"
if-stmt -> block-body
block-body -> "{"
block-body -> return-stmt
return-stmt -> "返回"
return-stmt -> add-expr
add-expr -> ""Hello, Mrs. ""
add-expr -> "+"
add-expr -> "姓名"
return-stmt -> "\n"
block-body -> "}"
if-stmt -> "否则"
if-stmt -> block-body
block-body -> "{"
block-body -> return-stmt
return-stmt -> "返回"
return-stmt -> add-expr
add-expr -> ""Hello, ""
add-expr -> "+"
add-expr -> "姓名"
return-stmt -> "\n"
block-body -> "}"
stmts -> "\n"
block-body -> "}"
decl-stmt -> "\n"
stmts -> decl-stmt
decl-stmt -> "定义"
element -> "输出"
element -> fcall
fcall -> "("
fcall -> element
element -> "拼接问候语"
element -> fcall
fcall -> "("
fcall -> expr
expr -> "姓名"
expr -> ","
expr -> "性别"
fcall -> ")"
fcall -> ")"
expr-stmt -> "\n"
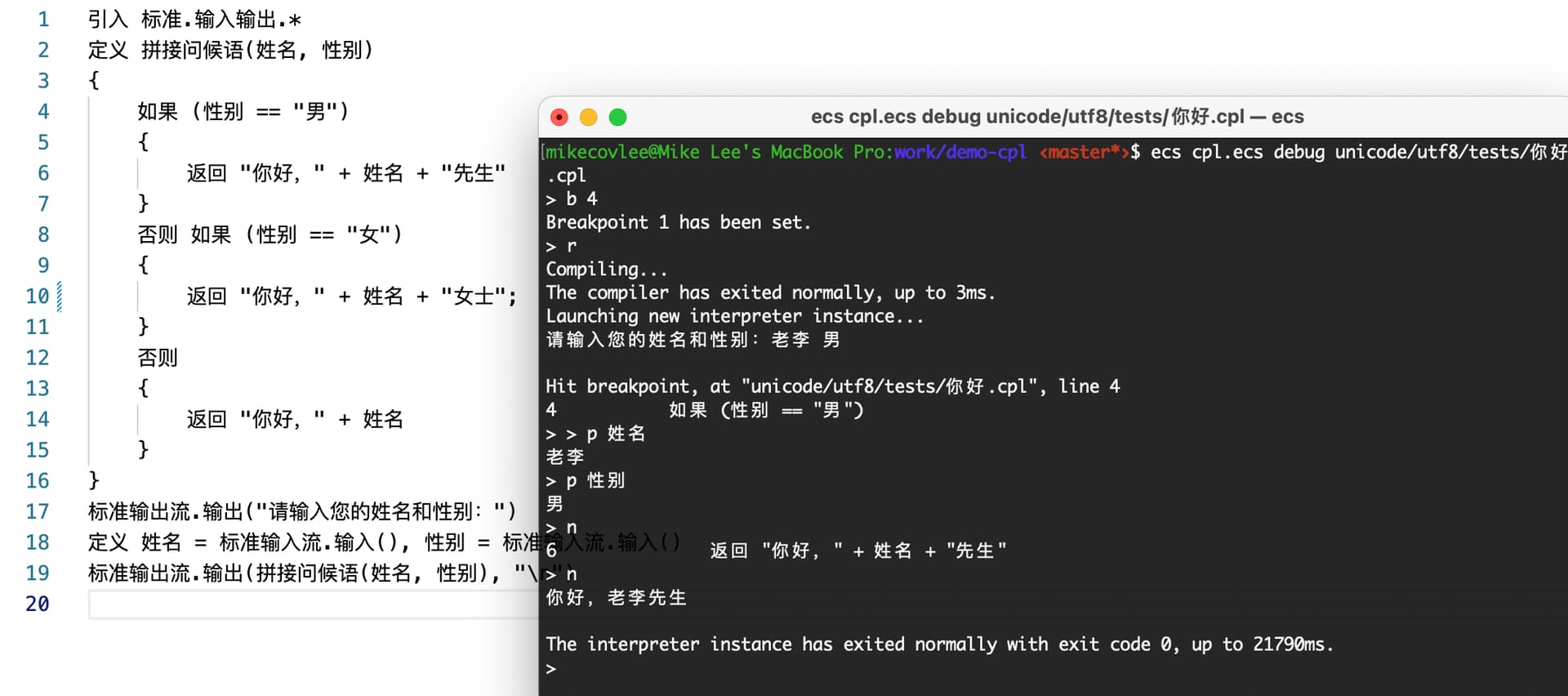
到这里,我们已经完成最简单的部分:解析语法并得到 AST
ParserGen 有两个版本,Release 版能用 CSPKG 直接下载,但仓库里还附带了一个 parsergen_debug.csp ,这个版本性能会差一些,但能通过 main.enable_log = true 输出整个分析过程,用来调试语法非常好用
下一步我们使用 ParserGen 附带的工具生成一个 AST Visitor,并在其基础上编写 CPL 的编译器
为了方便代码复用,我们把上面编写的语法规则独立放在一个 Package 里
unicode/utf8/imports/cpl_grammar.csp · 李登淳/Demo 中文编程语言 - 码云 - 开源中国 (gitee.com)
然后就可以非常方便的使用 ParserGen 的附带工具生成 AST Visitor 了
import cpl_grammar_utf8 as cpl
import visitorgen
var ofs = iostream.ofstream("./cpl_ast_visitor.csp")
(new visitorgen.visitor_generator).run(ofs, cpl.grammar.stx)
生成的 Visitor 比较大,这里放链接:
unicode/utf8/imports/cpl_ast_visitor.csp · 李登淳/Demo 中文编程语言 - 码云 - 开源中国 (gitee.com)
这个 Visitor 功能非常简单,就是把所有的树节点遍历并输出,但因为 ParserGen 为每个 AST 节点都生成了遍历函数,我们可以很方便的在其基础上构建编译器
事实上,ECS 就是用这种方法编写的
ParserGen 的 API 挺实用。
好像没看到优先级的设置?另外,ParserGen 有哪些报错信息呢?比如语法歧义等。
如果语言以此框架开发,使用中会有哪几类反馈信息(如报错等)呢?
不知道你说的是否是运算符优先级?若是的话,运算符优先级是通过上下文无关文法的递推产生的,不需要单独设置
目前 ParserGen 的报错还是有些短板,主要问题是在 LR Parsing 中移进错误不一定是真正的错误,若为了报错单独追踪整个推导链性能开销又比较高
ParserGen 的报错类似这样,其中 Incomplete sentence 是最常见也最 Tricky 的错误,实际上的触发条件是在 EOF 的时候还未能推导出完整的 AST
实际上,ParserGen 的报错是以 Error Log 的方式提供,每个 Log 会包含三个成员:
-
cursor: 分析器指针,指向词元数据的位置
-
text: 错误信息,字符串
-
pos: 位置,二元数组
基于 ParserGen 的语言若需要进行二次开发,只需要分析这个 Error Log 即可
这里再补充一下。关于 ParserGen 的语法规则,虽然整体来说更偏向于 LR,但实质上还是改进的 LL,所以无法完全解决左递归的问题,编写语法规则时要注意避免
现在开始改造 AST Visitor
实际上,ParserGen 生成的这个框架是专为代码生成和分析优化的。具体表现来说,首先整个遍历过程是完全遵循语法结构的,因此只需对着语法规则就能对框架进行修改;其次所有的输出全都是通过 target 成员变量来实现的,因此如果需要输出到其他位置,也可以灵活更改,甚至如果需要截取一部分代码生成结果,还可以把 target 临时指向一个 iostream.char_buff
在这里,我们需要处理的主要是引入语句和花括号,其他部分基本上将中文翻译成 CovScript 关键字就可以了
function visit_module_list(nodes)
var idx = 0
# Recursive Visit identifier
import_stack.front.push_back(nodes[idx++].nodes.front.data)
# Optional
if idx < nodes.size && (typeid nodes[idx] == typeid parsergen.token_type && nodes[idx].data == ".")
# Visit term "."
++idx
# Condition
block
var matched = false
if !matched && (typeid nodes[idx] == typeid parsergen.token_type && nodes[idx].data == "*")
matched = true
# Visit term "*"
++idx
import_stack.front.push_back("*")
end
if !matched && (typeid nodes[idx] == typeid parsergen.syntax_tree && nodes[idx].root == "module-list")
matched = true
# Recursive Visit module-list
this.visit_module_list(nodes[idx++].nodes)
end
if !matched
# Error
return
end
end
end
end
引入语句的处理,我们首先是在 moulde_list 中将原有的输出替换成暂时把列表内容保存起来
然后就是在 import_list 中提取这部分内容,给通配符加上 using 语句
import_stack.push_front(new array)
# Recursive Visit module-list
this.visit_module_list(nodes[idx++].nodes)
link pack = import_stack.front
import_stack.pop_front()
var wildcard = false
if pack.back == "*"
wildcard = true
pack.pop_back()
end
var str = new string
foreach it in pack do str += it + "."
str.cut(1)
if wildcard
target.println("import " + pack.front)
target.print("using " + str)
else
target.print("import " + str)
end
当然,我们还要进行一些错误处理,很明显我们不能允许通配符后使用别名
在进行错误处理之前,我们先给主类增加一个成员函数 error
function error(pos, text)
var err = new parsergen.lex_error
err.text = text
err.pos = pos
parsergen.print_error(file_name, code_buff, {err})
system.exit(0)
end
这个函数的作用非常简单,即构造一个 parsergen.lex_error 然后调用 ParserGen 的内置方法输出这个错误。当然,我们还需要给主类增加 file_name 和 code_buff 这两个属性,其中 code_buff 可以轻松从 ParserGen 中获得(parsergen.generator.code_buff,在parsergen.generator.code_buff.from_file 方法运行结束后会自动生成)
然后我们就可以进行错误处理了
# Optional
if idx < nodes.size && (typeid nodes[idx] == typeid parsergen.token_type && nodes[idx].data == "别名")
if wildcard
error(nodes[idx].pos, "在通配符后不允许使用别名")
end
# Visit term "别名"
++idx; target.print(" as ")
# Recursive Visit identifier
this.visit_identifier(nodes[idx++].nodes)
end
效果如下:
当然,ParserGen 在输出带有 Unicode 字符的文件内容时,下面的箭头指的不那么准,后面我会着手修复这个问题
更多改造过程,大家可以自己去看一下仓库,我就不在帖子里赘述了
现在把报错搞成这样了,因为对齐 Unicode 太困难
这个图标指向性挺好。
之前木兰重现里用的这个,回头换一下:
有了 cSYM 就能准确报错了,虽然现在还没办法 Hack 到解释器里把报错翻译了,但至少能报错到正确的位置
1 个赞
以endline为例,这里展示一下如何生成cSYM
function visit_endline(nodes)
var idx = 0
# Condition
block
var matched = false
if !matched && (typeid nodes[idx] == typeid parsergen.token_type && nodes[idx].type == "endl")
matched = true
# Visit endl token
++idx; target.println(""); csym_map.push_back(nodes[idx - 1].pos[1] - 1)
end
if !matched && (typeid nodes[idx] == typeid parsergen.token_type && nodes[idx].data == ";")
matched = true
# Visit term ";"
++idx; target.println(""); csym_map.push_back(nodes[idx - 1].pos[1])
end
if !matched
# Error
return
end
end
end
这里 csym_map 是一个数组,我们只需要在每次打印换行的时候同步在数组里添加一个对应的行号就可以了。ParserGen 会自动给所有的词元插入位置信息,所以我们只需要定位到最近的词元并通过 pos 成员拿到所在的行号
这里有一个小 Tricky,对于换行符来说,应该把行号减一,否则就对应到下一行去了